

在广州与两位合伙人到访了六家企业,收获丰硕,不愧是资深的FA威而鋼

FA的工作,我想stay active,做点利已利人的事。成故欣然败亦可喜。起码学点东西也交了朋友。


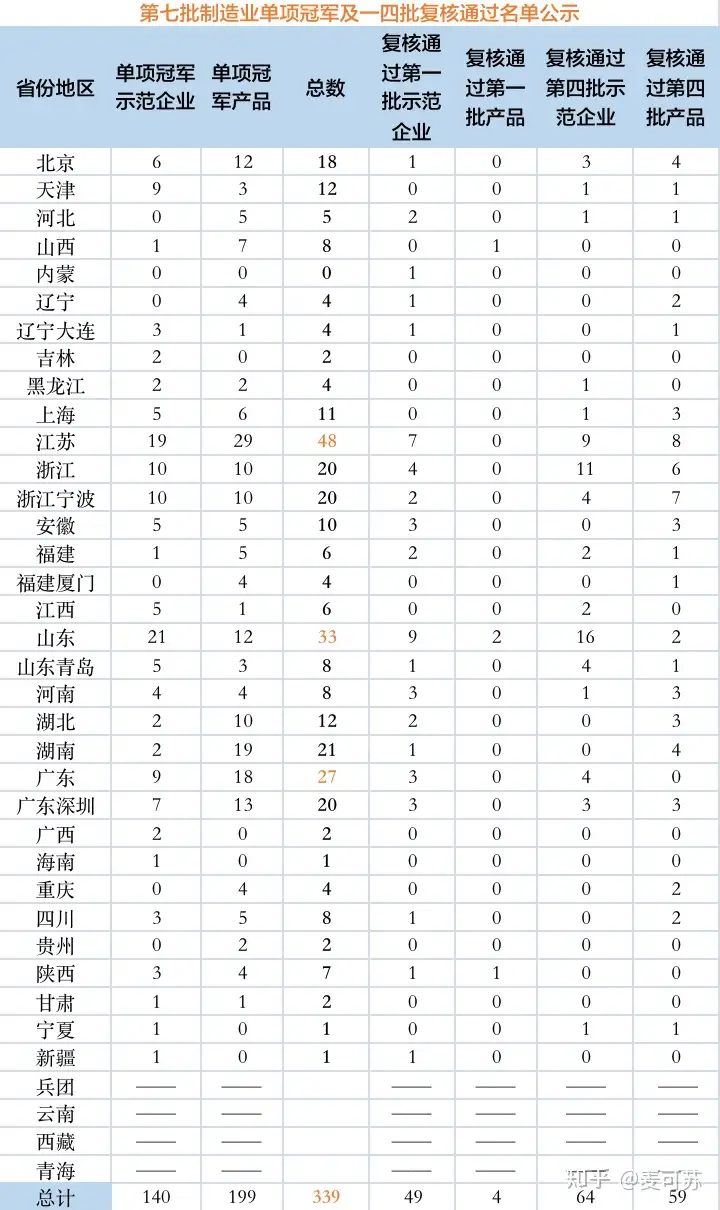
为贯彻落实《关于加快培育发展制造业优质企业的指导意见》(工信部联政法〔2021〕70号),根据《工业和信息化部办共厅 中国工业经济联合会关于开展2022年制造业单项冠军企业(产品)培育遴选和复核评价工作的通知》(工信部联政法函〔2022〕47号),工业和信息化部、中国工业经济联合会组织开展了第七批制造业单项冠军企业(产品)培育遴选和第一批、第四批制造业单项冠军企业(产品)复核工作。
公示时间:2022年10月24日至10月31日
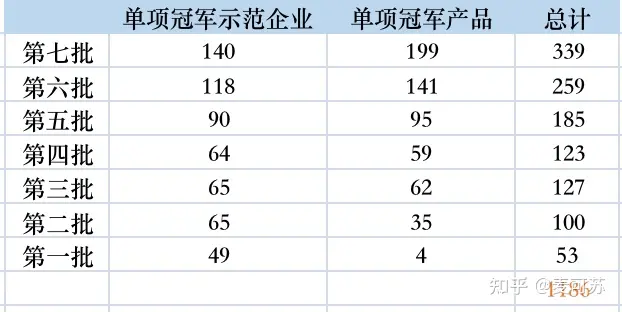
现整理各地区公布的第七批制造业单项冠军,及第一第四批审核通过名单汇总如下:

Since dating can be stressful, there is the possibility of humor to try to reduce tensions. In a new study published in the Proceedings of the National Academy of Sciences, Rosenfeld found that heterosexual couples are more likely to meet a romantic partner online than through personal contacts and connections. Since 1940, traditional ways of meeting partners – through family, in church and in the neighborhood – have all been in decline, Rosenfeld said. The company has said that this app is single, progressive and specially designed for the Gen Z market.
So it’s taken that pressure off, this has to be a friendship interaction, and this has to be a romantic interaction. The platforms highlighted below are legal, so you don’t have to worry about getting scammed. OurTime.com is a dating site that caters to singles 50 years and older. Registration is free, and you can view profiles of singles in your area. The app is easy to use, and you can connect with local singles that interest you. Starting a conversation here is very easy because your potential matches are meant to comment on a specific piece of information on your profile.
They are oriented on varied countries and on the varied nationalities. There hookupguru the sites with the diverse prices and the diverse functionalities. You will need a premium membership to use the site’s full potential. For example, messaging people as a free member lets you only use the message feature to send site-generated icebreakers, while Standard members can only send winks and add folks to their favorites.
So until then, I’m delighted and would like to say thank you towards the present software for providing usa together. I got most positive and negative experiences previously, and many consumers actually shattered the emotions.
The date can be online or physical, with the latter costing the paying party any expenses incurred during the meet-up. If the date is to take place in a venue that requires an entry fee, your partner should pay for that too. As to how much you get to take home, the going rate averages $80 to $100 per date. Also, as an attractive member, you have an option to negotiate the bid if you feel the amount is too. After submitting your request, you’ll receive a confirmation email giving you access to the site. This is an adult dating website where bids are placed to win a date.
Reverting to characteristics of traditional sexual scripts, women may find themselves further entrenched in unwanted gender roles. Feminist Gail Dines has opined that pornography is “a cultural force that is shaping the sexual attitudes of an entire generation” and a “major form of sex ed today for boys.”
Most importantly, you get to set the budget for the entire date. What this means is that you get to keep the full-price amount. Finally, you don’t have to disclose your personal identity if you are not comfortable with a bidder. For the chance to get paid to date a millionaire or just the average Joe, you pay a subscription fee of $59.99 for 30 days.
Basically, you’re given a random profile with the option to either “like” them or “X” cross them out – sort of like Tinder’s swipe feature. Most of the members on SearchingforSingles are from the US, but you can still find users worldwide! Plus, there are also more women than men on this hookup site, if that’s what you’re after. Tinder has been called the harbinger of the hookup-fueled “dating apocalypse.” But the truth of the matter is, hooking up isn’t anything new . And as for Tinder, sure, it can be used for swiftly finding a one-night stand, but there are plenty of other apps that are better suited for that task. You don’t have to travel thousands of miles away to meet your date when you find the perfect match – as Tinder lets you only access singles near your location.
Since dating can be stressful, there is the possibility of humor to try to reduce tensions. In a new study published in the Proceedings of the National Academy of Sciences, Rosenfeld found that heterosexual couples are more likely to meet a romantic partner online than through personal contacts and connections. Since 1940, traditional ways of meeting partners – through family, in church and in the neighborhood – have all been in decline, Rosenfeld said. The company has said that this app is single, progressive and specially designed for the Gen Z market.
So it’s taken that pressure off, this has to be a friendship interaction, and this has to be a romantic interaction. The platforms highlighted below are legal, so you don’t have to worry about getting scammed. OurTime.com is a dating site that caters to singles 50 years and older. Registration is free, and you can view profiles of singles in your area. The app is easy to use, and you can connect with local singles that interest you. Starting a conversation here is very easy because your potential matches are meant to comment on a specific piece of information on your profile.
They are oriented on varied countries and on the varied nationalities. There hookupguru the sites with the diverse prices and the diverse functionalities. You will need a premium membership to use the site’s full potential. For example, messaging people as a free member lets you only use the message feature to send site-generated icebreakers, while Standard members can only send winks and add folks to their favorites.
So until then, I’m delighted and would like to say thank you towards the present software for providing usa together. I got most positive and negative experiences previously, and many consumers actually shattered the emotions.
The date can be online or physical, with the latter costing the paying party any expenses incurred during the meet-up. If the date is to take place in a venue that requires an entry fee, your partner should pay for that too. As to how much you get to take home, the going rate averages $80 to $100 per date. A樂威壯
lso, as an attractive member, you have an option to negotiate the bid if you feel the amount is too. After submitting your request, you’ll receive a confirmation email giving you access to the site. This is an adult dating website where bids are placed to win a date.
Reverting to characteristics of traditional sexual scripts, women may find themselves further entrenched in unwanted gender roles. Feminist Gail Dines has opined that pornography is “a cultural force that is shaping the sexual attitudes of an entire generation” and a “major form of sex ed today for boys.”
Most importantly, you get to set the budget for the entire date. What this means is that you get to keep the full-price amount. Finally, you don’t have to disclose your personal identity if you are not comfortable with a bidder. For the chance to get paid to date a millionaire or just the average Joe, you pay a subscription fee of $59.99 for 30 days.
Basically, you’re given a random profile with the option to either “like” them or “X” cross them out – sort of like Tinder’s swipe feature. Most of the members on SearchingforSingles are from the US, but you can still find users worldwide! Plus, there are also more women than men on this hookup site, if that’s what you’re after. Tinder has been called the harbinger of the hookup-fueled “dating apocalypse.” But the truth of the matter is, hooking up isn’t anything new . And as for Tinder, sure, it can be used for swiftly finding a one-night stand, but there are plenty of other apps that are better suited for that task. You don’t have to travel thousands of miles away to meet your date when you find the perfect match – as Tinder lets you only access singles near your location.
这也是国内目前科学界阵容最强大、领域跨越最广、影响力最大的青年科学家学术交流平台之一。
此次论坛以“聚焦原创,突破边界”为主题,希望通过搭建科学家代际之间、领域之间的交流平台,瞄准“从0到1”的原始创新,鼓励跨领域、跨学科的交叉研究合作,全方位支持青年科学家的成长与发展。
论坛上,由“科学探索奖”获奖人提出并投票产生的2022年度“十大基础研究关键词”发布,体现出以获奖人为代表的中国杰出青年科学家群体,对未来科技发展的前瞻研判,和对“从0到1”的原始创新的不断探索。
多位顶尖科学家回国后首次现身
“于微纳处天地宽”。在“学术演讲”环节,六位在生物技术、生命科学、结构生物学、复杂科学研究、分子细胞科学、信息电子等领域具有重要建树的科学家分享各自研究领域的探索最前沿,碰撞跨界研究火花。
美国科学院院士、著名植物生物学家朱健康带来了“从DNA第五碱基到健康与长寿”的学术分享。朱健康是世界植物科学领域发表文章引用率最高的科学家之一,同时也是爱思唯尔发布的最新版“全球顶尖科学家排名”榜单中排名最高的中国科学家。朱健康主要从事植物对抗逆境研究,也就是植物为何能够抗旱、耐盐与耐低温,并将这样的能力遗传给下一代,这些研究在基因编辑作物、植物育种等方面发挥了巨大作用。今年1月,朱健康加入南方科技大学担任前沿生物技术研究院院长。在今天(27日)的论坛上,他结合自己的工作,讲述了基因序列里看不到的遗传信息,“DNA甲基化”的神奇作用,拨慢“DNA甲基化时钟”,有可能延缓衰老,健康长寿。
朱健康在论坛现场分享
西湖大学生命科学学院院长、西湖实验室主任于洪涛是全球著名细胞生物学家,他长期从事最基本的生命现象细胞分裂研究,曾在全球首次找到细胞分裂的“开关”纺锤体检查点。本次论坛也是他在2019年全职回国后,为数不多的公开学术报告。在今天的论坛上,他与听众们分享了细胞分裂的神奇旅程,和在这一过程中,“生命密码”基因组的传承和塑造。
于洪涛在论坛现场分享
人工智能和大数据技术被认为正在成为当今科学发现的新范式。AlphaFold2在2021年横空出世,点燃AI for Science热潮。AI技术一举将蛋白质3D结构预测的精度从60%提升到90%以上,也入选了《science》杂志评选的2021年度最重要的科学突破之一。但人工智能是否真的无所不能?国际著名结构生物学家颜宁的报告另辟蹊径,通过阐释AI在结构生物学中的未达之地,为人们理解AI for Science提供了全新的视角。
颜宁在论坛现场分享
同时,不少从事基础研究的学生也通过这场线上论坛感受杰出科学家们的学术“点拨”。一早就守直播的南方科技大学研究生秦同学这一天内记了好十几页笔记。“以前只能在学术期刊见到的科学家名字,这次居然能现身给我们作分享,我们同学都很振奋。我希望自己能更有耐力地在基础研究领域攻坚克难,以‘十年磨一剑’的态度对待我的研究。”他表示。
六所顶尖高校分享“育人之道”
本次论坛新增“校长圆桌”。围绕如何“引导、支持从事基础研究的青年教师甘坐冷板凳、探索长周期重大科学问题”等议题,南方科技大学校长薛其坤、 东方理工高等研究院院长陈十一、哈尔滨工业大学校长韩杰才 、上海科技大学党委书记李儒新、大湾区大学(筹)负责人田刚、厦门大学校长张宗益共同探讨中国高校上下求索之道。
校长圆桌论坛
大学是科学发现和重大基础发明的摇篮。对于高校而言,拔尖创新人才的培养是一流大学的核心使命,也代表着高等教育和大学对国家与社会的主要贡献力。
而对于企业而言,任何一家有竞争力的高科技企业都得益于创新,也同样重视拔尖创新人才培养。腾讯集团高级副总裁、首席人才官奚丹在论坛上坦言,“没有原始创新的深厚地基,没有高水平科技自立自强,科技企业的大厦再高大再漂亮,也难以经受风吹雨打。”过去几年,腾讯把“推动可持续社会价值创新”纳入公司战略,支持基础科研是重中之重。从设立科学探索奖,到举办青年科学家50²论坛,再到今年新发起新基石研究员项目,腾讯不断加大以公益形式投入基础科研领域。奚丹表示,“在出资之外,我们还希望为探索奖获奖人精心准备一个高水平的学术交流平台,满足青年科学家跨学科交流的需要,这就促成了青年科学家50²论坛。”奚丹介绍,助力国家基础科研的长远发展,是腾讯超越商业边界的一份长期承诺,将十年如一日地坚持“甘当绿叶扶红花”的社会担当。
奚丹在论坛现场分享
在中国科学院院士、科协名誉主席韩启德看来,将“科学探索奖”获奖者作为中国优秀青年科学家的样本,通过研究他们的成长规律与创新机制,亦或能为高水平科技人才的培育贡献一些可借鉴的经验。于是在韩启德的提议下,北京大学联合科学探索奖项目组共同发起了“基于科学探索奖的青年科技人才成长规律”的研究项目,以研究科学探索奖的成功经验为基础,希望为改进科研考核评价和激励制度提供参照;同时揭示当代中国青年科学家得以成功的内在与外在因素,为我国科学教育事业的创新发展献计献策。
拔尖创新人才的培养,自然离不开政府的政策支持与资金支持。也只有教育界与社会各界形成合力,才能共同破解萦绕在科学教育领域的“钱学森之问”。
2022年6月14日,国务院印发《广州南沙深化面向世界的粤港澳全面合作总体方案》(简称《南沙方案》)。方案提出,要加快推动广州南沙深化粤港澳全面合作。方案按照以点带面、循序渐进的建设时序,以中国(广东)自由贸易试验区南沙片区的南沙湾、庆盛枢纽、南沙枢纽3个区块作为先行启动区,总面积约23平方公里。作为该片区龙头国企主导的标杆产业园项目 ,生逢其时,迎来巨大发展利好。
庆盛枢纽,自贸区、粤港合作园、
启动区,万千宠爱于一身
这一次《南沙方案》将庆盛枢纽区块作为先行启动区,对先行启动区鼓励类产业企业减按15%税率征收企业所得税;个人所得税方面,对在南沙工作的港澳居民,免征其个人所得税税负超过港澳税负的部分等政策,其对高端科技人才的吸引力进一步凸显,庆盛片区可谓是当之无愧的集万千宠爱于一身。
穗港协同,龙头国企、世界级高校,
科技独角兽策源地
产学研深度协同,港科大创新企业,
向基地聚集
《南沙方案》提出“加强香港科技大学科创成果内地转移转化总部基地等项目建设,积极承接香港电子工程、计算机科学、海洋科学、人工智能和智慧城市等领域创新成果转移转化,建设华南科技成果转移转化高地。”

基金+基地,全新园区模式,
对科技企业形成强引力
面向世界,聚焦湾区,

Welcome to China in 2022
How to Work and live in China Now?
Very Easy:
Doctor’s degree certificate, and the certificate issued by the overseas study service center of the Ministry of education shall be provided for foreign university graduates;
You can apply now:hellohb@msn.com (CV)


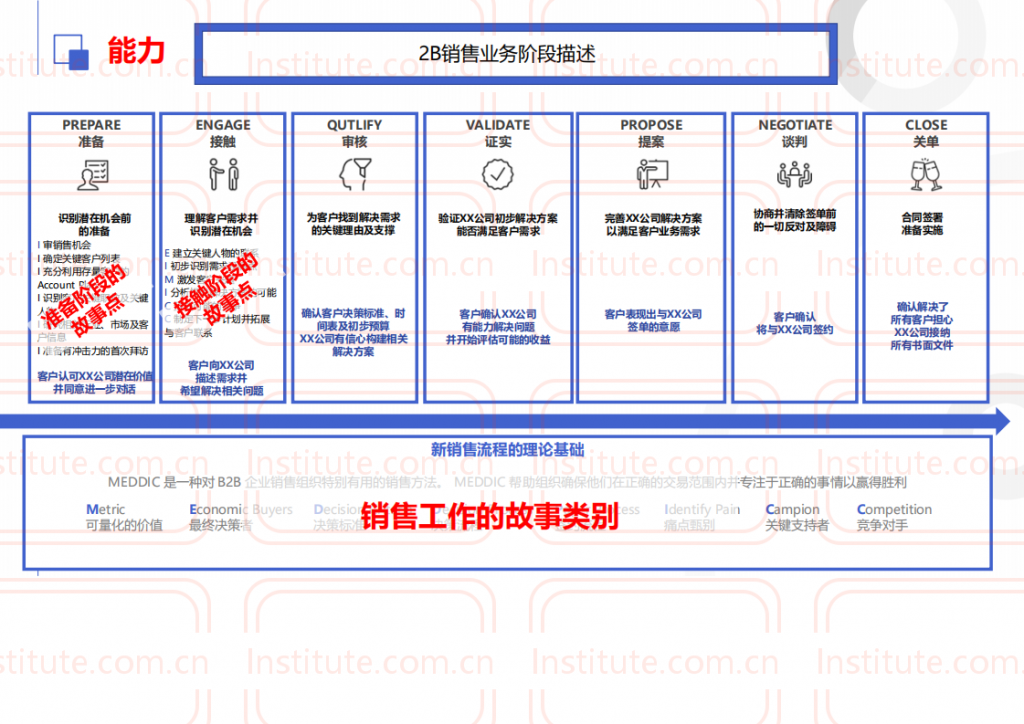
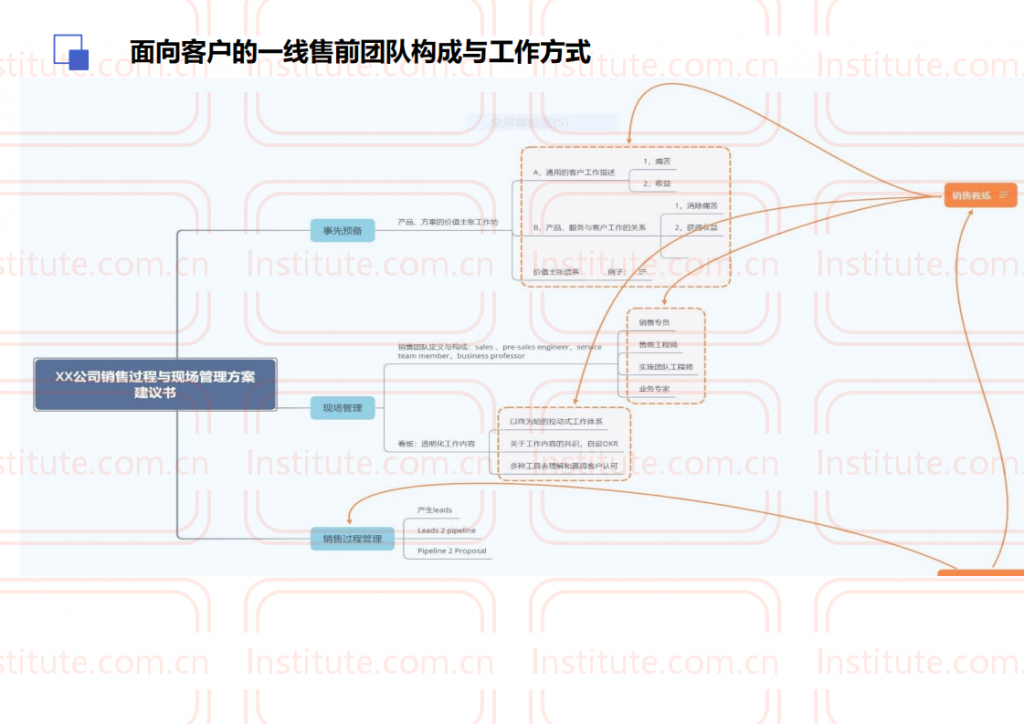
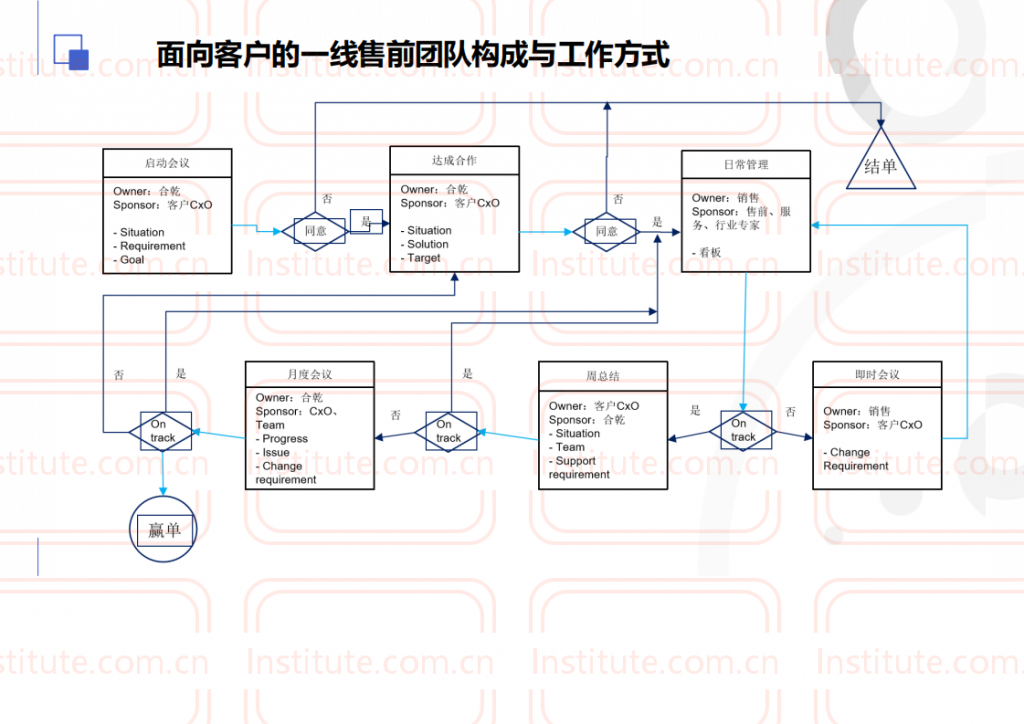






原创 大强 大强旅行分享
本文从业务人员便于理解的角度来介绍 BIAN,与 BIAN 官方对其体系的解释有一定出入,仅供参考。
什么是开放银行
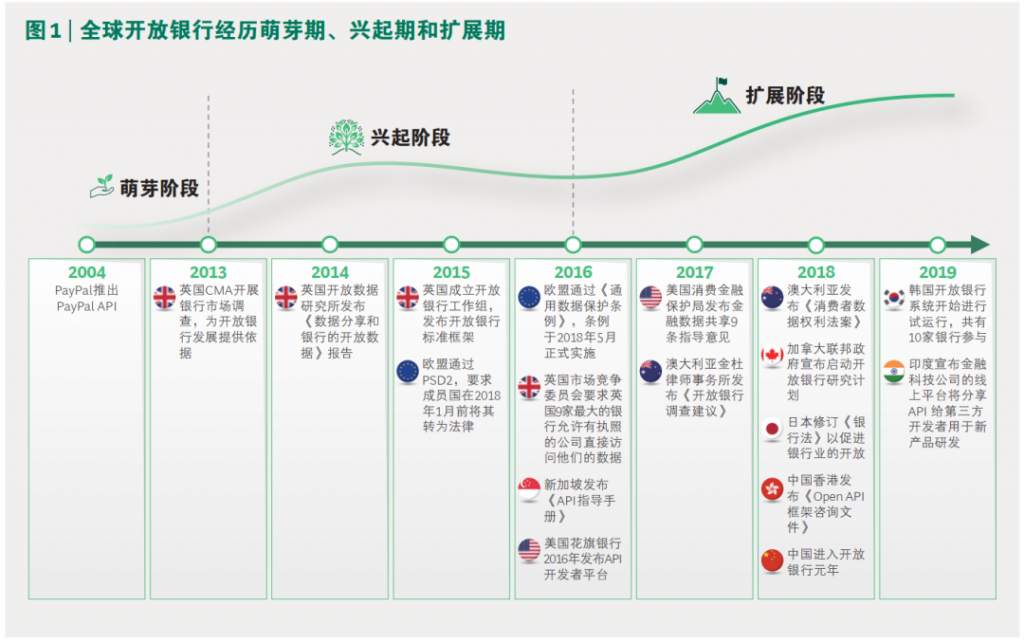
开放银行 Open Banking 是一个金融服务术语,作为金融技术的一部分,指的是[1] :
开放银行正在全球范围内发展,许多国家都在研究如何通过 Open API 共享和管理金融数据。[2] 今天,全世界有60多个国家制定了开放银行解决方案,有一系列的产品和服务、实施时间表和数据访问范围的规定。[3]中国人民银行在 2020年发布了《商业银行应用程序接口安全管理规范》,从技术角度为开放银行监管开启了第一步,但当前尚未出台相关法律法规以明确开放银行发展模式。中国内地银行业主要基于提升自身市场竞争力和获客能力的角度,在现有监管框架下,积极寻求生态合作伙伴,借助金融科技手段,将自身金融产品嵌入场景,拓宽业务渠道,对外输出金融服务能力。以2018年为始点,浦发银行、建设银行、平安银行、微众银行和新网银行纷纷推出开放银行平台,从平台建设、场景生态合作等方面积极探索开放银行服务模式。[4]
BIAN ( The Banking Industry Architecture Network) 是一个业界多方协作的非营利性组织,由全球领先银行、技术提供商、顾问和学者组成,定义了一个用以简化和标准化核心银行体系结构的银行技术框架。这一框架基于面向服务的架构 (SOA) 原则,银行可以借助 BIAN 参考模型建立起业务能力“积木块”,通过与现有系统进行映射和对接,理清应用之间的边界,从而达成面向服务的、松耦合的未来银行架构。从架构及技术角度看, BIAN 融汇了业界关于银行业务模型和技术体系的积累、结合 SOA 架构和微服务架构理念,基于业务能力、组件及服务而形成的银行应用之间互联互通的技术标准。[5]
BIAN 的业务能力
从业务架构的角度来看,BIAN 提供了两个重要的企业架构工件,一个是业务能力地图 Business Capability Map,一个是价值链 Value Chain。
BIAN 的业务能力地图一共分为三级,呈现了银行“能做什么”。银行可以此为参考,根据自身业务情况进行对齐和调整。BIAN 业务能力地图是一个多级嵌套结构,大部分可以到三级,部分能力细分到四级,能力划分的颗粒度比 BIZBOK 的金融参考模型要细得多。第一级是能力分类,包括:

BIAN 业务能力地图 Level 1 ~ Level 2
(点击图片放大)

BIAN 业务能力地图明细
BIAN 的业务能力地图构建方式与普通企业架构实践是有区别的。一般情况下,业务架构设计过程中会集中业务和分析师等人员,采用自上而下逐步分解的方式构建业务能力地图。而 BIAN 的业务能力地图,是由一系列已经构建完成的原子级能力,通过映射的方式汇总为业务能力地图。主要的目的是为了与业务架构进行对齐,以适配主流的业务架构分析方法。
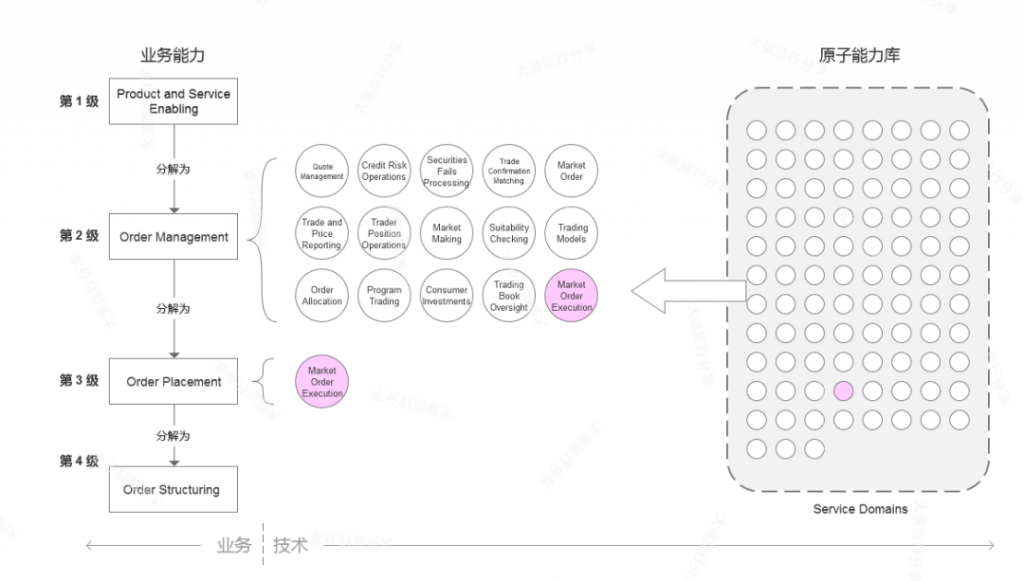
服务域(BIAN 称为 Service Domain,俺称为原子能力)代表一组离散的、原子的(唯一/不重叠的)业务功能,它们构成了任何银行的功能构建块 (Functional Building Blocks),用于为解决方案的开发提供业务功能框架。服务域和业务能力为明显不同的目的而将业务区分开来。服务域是一种功能细分,旨在提供一个开发/部署框架。业务能力代表了不同的业务所拥有的能力,目的是制定和实施业务战略。[6]

BIAN 服务域可以被认为是 “对某物做某事的能力”,专注于对一个业务对象所执行的操作。BIAN 服务域是原子性的,这意味着 “代表了可以被服务化的最小实际能力或功能分区。” 换句话讲,一个服务域将封装适合(被封装到) IT 服务中的最小实际业务功能 Business Functionality 。在某些情况下,服务域直接(或几乎)与业务能力相一致;然而,由于服务域是面向功能的,它们通常与价值流 Value Stream 有关,或者更经常地与价值流阶段 Value Stream Stage(或其一部分)有关。
BIAN 的价值链
构建业务能力地图,比想象的要难。不信?可以尝试为自己所在公司创建一张业务能力地图:第一,你会在 What 和 How 之间做很长的思想斗争;第二,到底啥是你脑海中的某个业务能力,你想的这个真的是业务能力吗?第三,在深入到 3 级以下业务能力切分的时候,业务能力已经与任务开始混杂在一起了,不好定义。
企业架构实践中有一个误解,就是在业务架构环节一定要产出业务能力地图。是否产出能力地图,这个要看企业领导和业务层的习惯,如果多数人更擅长理解价值链,那就用价值链作为沟通工具,最终目的是为了方便沟通达成共识。价值链不知道是啥?没关系,业务流程大家都懂。
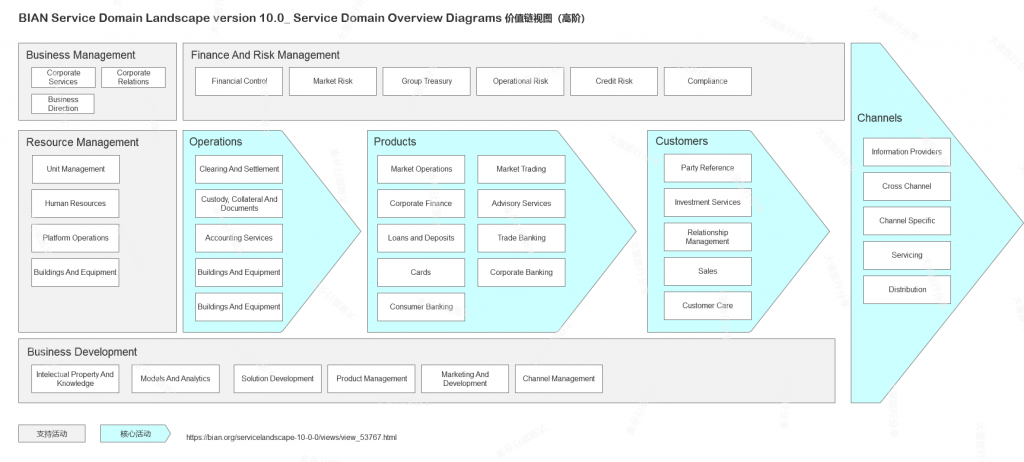
BIAN 价值链(点击图片放大)
BIAN 的价值链并不是真正的价值链,因为价值链是要进行更下一步分解的,但是 BIAN 仅分解到第 2 层就戛然而止。BIAN 使用价值链视图的真正目的,是给银行另外一个看待原子业务能力的视角。注意下图中的第 3 级,已经不是呈现的活动的分解,而是服务域 Service Domain 这种原子能力。[7]

BIAN 价值链明细图(点击图片放大)
BIAN 到底是什么
经过多年积累,BIAN 为银行业务构建了一批原子业务能力,使银行在信息化建设的过程中可以利用 BIAN 的行业框架,依据自身实际情况进行调优后,便捷高效地实施数字化战略。BIAN 构建了便于业务侧理解的业务能力地图与价值链,将原子业务能力通过映射的方式与两个业务架构中的关键工件进行关联,从而实现银行的业务与 IT 对齐。原子能力便于组装的特性,极大地促进了业务侧的创新与调整;通过统一规范的接口,为银行铺就了一条互联互通的开放之路。
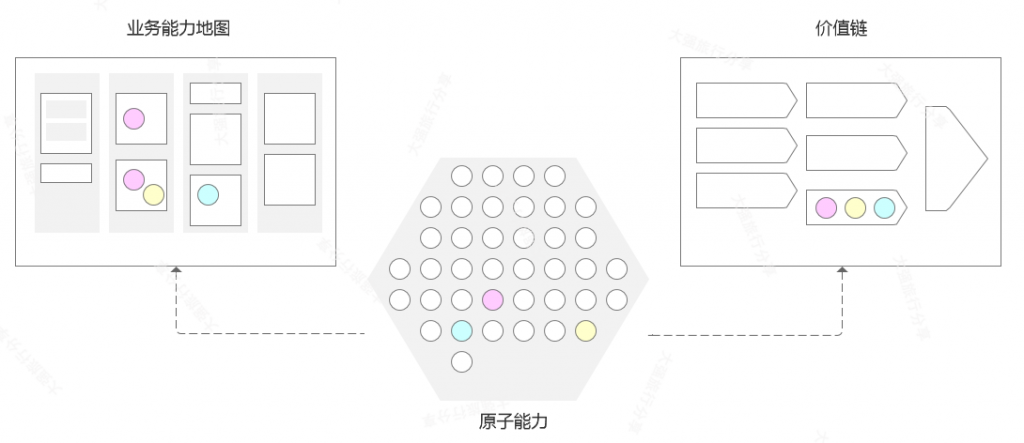
学会了什么
作为业务分析师,俺对业务流程分析有着天然的好感。学习 BIZBOK 后,知道业务能力地图很重要,但是它为什么重要呢?它到底决定了什么?以前没有业务能力地图,也一样把系统成功交付上线。凭什么学个业务架构,就非得去搞这个业务能力地图呢?
这是因为微服务体系结构中的服务,是围绕业务问题进行组织的——业务能力或业务子域,而非技术问题。应用分解为服务有两种方式:按业务能力分解或者按业务子域分解。前者基于业务架构设计中产出的业务能力地图,后者基于领域驱动开发的设计环节。[8]
领域驱动设计 DDD,是一种自下而上的方式。同时需要业务人员、领域专家、业务分析师、开发、架构师等共同参与。两种方式设计的结果可能极其相近,但创建业务能力地图的效率会更高,更容易被理解,更容易被业务参与。
业务能力地图设计可以脱离技术在业务端独立完成,是一种自上而下的方式,它展现了完整的业务视角。业务能力通常集中在特定的业务对象上。每个业务能力都可以被视为一种服务,但它是面向业务而非技术性的,其特性包括输入、输出和服务级别协议。一旦在业务架构分析中确定了业务能力,就可以为每个能力或一组相关能力定义一个服务。最终的成果是围绕业务概念而不是技术概念组织服务。
围绕业务能力组织服务的一个关键好处在于业务架构是相对稳定的,所以后续产生的架构设计也是相对稳定的。

业务能力产出决定了服务的设计
The End.
参考资料:
1. Wiki: Open Banking, https://en.wikipedia.org/wiki/Open_banking
2. The World of Open Banking, https://www.konsentus.com/resources/the-world-of-open-banking/
3. Open Banking Series: Market-Driven vs. Regulatory-Driven, https://www.pymnts.com/news/digital-banking/2021/open-banking-series-market-driven-vs-regulatory-driven/
4. 中国开放银行白皮书2021-波士顿咨询公司与平安银行联合研究
5. BIAN (Banking Industry Architecture Network) —— Weaving the Value Net of Digital Banking Ecosystem,IBM,李纪华
6. Using Business Architecture in Conjunction with BIAN Service Domains to Drive Business Value, Business Architecture Guild, 2021
7. BIAN 2nd Edition, 2021
8. Microservices Patterns With Examples in Java, Chris Richardson, 2019